AI Stressing All Technology Tiers
The enormous universe of big data refers to data sets so large or complex that most traditional data management tools can’t store or process them efficiently. Big data applications can generate data faster than it can be analyzed, significantly extending data retention timeframes and filling data lakes which have no size limits. AI is now squarely in the spotlight and is leading the race to harvest the massive troves of unstructured big data, much of which resides on secondary storage. The impact of AI on future storage demand has not been determined, but it will undoubtedly be huge.
As AI fuels the dawn of disruption and big data stores, data lakes and multi-petabyte archives have become its primary input data source. It is estimated that approximately 97 percent of businesses are investing in AI and ML technology to mine big data. This bodes well for AI, which can feast on even larger data stores to build its complex training models.
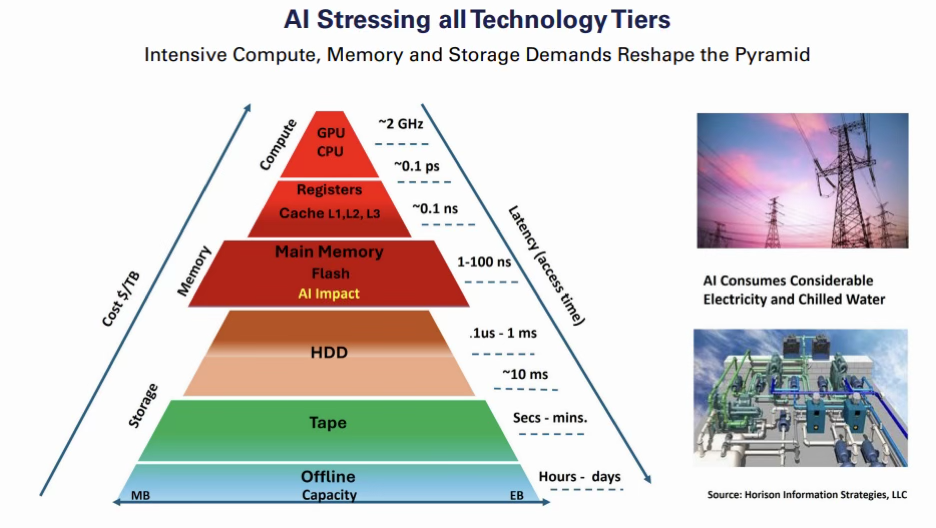
Barring any significant slowdown in AI deployment, AI will impact every technology tier with heaviest impact on compute (GPUs), memory (DRAM), and flash SSD. HDD and tape will see demand increases to store, retrieve, archive, and protect all AI output. AI also requires huge amounts of water and electricity to cool the red-hot running GPUs, further exacerbating the data center energy challenges to manage and reduce energy consumption.
Estimates suggest that high-end GPUs are consuming as much electricity as several small countries and are responsible for huge portions of new electricity demand in the US. By 2027, AI servers could use between 85 and 134 TWh annually, similar to Argentina, the Netherlands, or Sweden. This is clearly not a sustainable trend going forward.
Consider that a simple Google text-based search can require approximately 0.5 MB of DRAM (Main Memory) compared to an AI chat model, which can require up to 1 TB to run a prompt, significantly increasing memory requirements. Then consider the memory impact if a high percentage of today’s Google searches are replaced by chat models. Typical ChatGPT models have around 1.8 trillion data points, but smaller models with only approximately 2.5 billion data points are emerging that can still provide enterprises with good results while cutting down energy consumption. AI training consists of a three-step process.
The training step normally involves humans adding metadata to unstructured data which is fed into an algorithm to create predictions and evaluate their accuracy. The validation step evaluates how well the trained model performs on previously untouched data, typically residing on secondary storage. Finally, testing is done to decide if the final model makes accurate predictions with new data that it has never seen before. These are very compute, storage, and energy intensive processes.
Fred Moore is a Technical Advisor to the LTO Show and Principal at Horison Information Strategies in Boulder, Colorado, a data storage industry analyst and consulting firm that specializes in keynote speaking, executive briefings, marketing strategy, and business development for end-users and storage hardware and software suppliers. Please reach out with story ideas or comments, we’ll respond to each directly at pete@ltoshow.com
Copyright 2026 The LTO Show and Pete Paisley
Linear Tape-Open LTO, the LTO logo, Ultrium, and the Ultrium logo are registered trademarks of Hewlett Packard Enterprise, IBM, and Quantum in the US and other countries. All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.